AgentVault — CLI-First RAG for Local Codebases
What AgentVault is (in one paragraph)
AgentVault is a local-first, CLI-first retrieval layer for working with large repositories alongside coding agents. The goal is simple: index a codebase once, then answer questions by retrieving a small, high-signal slice of context instead of repeatedly scanning files. That makes agent workflows faster, cheaper, and much easier to reproduce.
The design problem I cared about
When an agent’s default strategy is “read more files,” quality often improves—but the workflow doesn’t scale. The bigger the repo gets, the more you pay in latency and tokens, and the harder it becomes to explain why an answer was produced (or to get the same answer twice).
AgentVault is my attempt to turn that into an engineering system: deterministic inputs, explicit indexing, auditable outputs, and a clean boundary between domain logic and integrations.
Architecture choice: ports-and-adapters (hexagonal), on purpose
I chose a ports-and-adapters architecture to keep the core behavior stable while allowing storage and model providers to change over time. All external dependencies are expressed as interfaces (ports) in the core. Concrete implementations live in adapter packages, and the CLI wires them together.
The intent isn’t academic purity—it’s practical leverage:
- Testability: core services can be unit-tested by mocking ports.
- Maintainability: the CLI stays thin and doesn’t “grow business logic.”
- Extensibility: swapping providers/storage doesn’t force a rewrite of the domain.
At runtime, everything is assembled in one composition root (apps/cli/src/runtime.ts), which constructs adapters and injects them into services. CLI command handlers (apps/cli/src/commands/*.ts) are intentionally boring: parse flags, call a service, format output.
Retrieval design: hybrid search + rank fusion
Developer questions are a mix of semantic and lexical intent:
- Sometimes you want meaning (“where is auth enforced?”).
- Sometimes you need exact tokens (“JWT”, function names, config keys).
So AgentVault runs two retrieval strategies in parallel:
- Vector search (cosine similarity over embeddings)
- BM25 keyword search via SQLite FTS5 (Porter stemming)
Then it merges results using Reciprocal Rank Fusion (RRF). I like RRF here because it’s rank-based, which avoids comparing incompatible scoring scales (vector similarity vs BM25 relevance). With a default k=60, each candidate chunk gets:
1/(k + vectorRank) + 1/(k + bm25Rank)
The high-level pipeline:
embed query → vector search + BM25 search → RRF rerank → context reduction → grounded answer
Storage: local-first, inspectable, minimal friction
I leaned into SQLite because it’s portable, debuggable, and already excellent at text search. The database lives under ~/.agents-vault/agents-vault.sqlite:
- FTS5 provides the BM25 keyword index
- Vector similarity is computed in TypeScript (no vector extension required)
That “no vector extension” decision is deliberate: it lowers installation friction and keeps the tool usable anywhere Node runs.
Ingestion: staged pipeline with explicit escape hatches
Ingestion is modeled as a clear pipeline so each stage can be inspected and swapped:
FileScanner → ParserFactory → DefaultChunker → EmbeddingProvider → VectorStore
Current defaults are tuned for practical retrieval and citation granularity:
- Chunking: ~800-token window with ~120-token overlap
- Checksums prevent redundant ingestion and enable incremental updates
--reindexforces a full refresh when that’s the right tradeoff
Determinism, automation, and “engineering ergonomics”
Because AgentVault is meant to be called by tools and agents (not just humans), the CLI behavior is optimized for automation:
- deterministic, script-friendly outputs
- non-zero exit codes on errors
- conversation export as Markdown logs for auditability
Configuration is also intentionally explicit:
- Non-secret config:
~/.agents-vault/agents-vault.json - Encrypted auth vault:
~/.agents-vault/auth.json+ local key~/.agents-vault/auth.key - No automatic
.envloading—export variables in your shell or use interactive configuration
Download / install locally
Install from npm (recommended)
npm install -g agents-vault
agents-vault --help
Build and run from source
pnpm install
pnpm build
node apps/cli/dist/index.js --help
Quick start (end-to-end)
agents-vault configure
agents-vault ingest --source ./docs --project my-project
agents-vault ask "How does auth work?" --project my-project
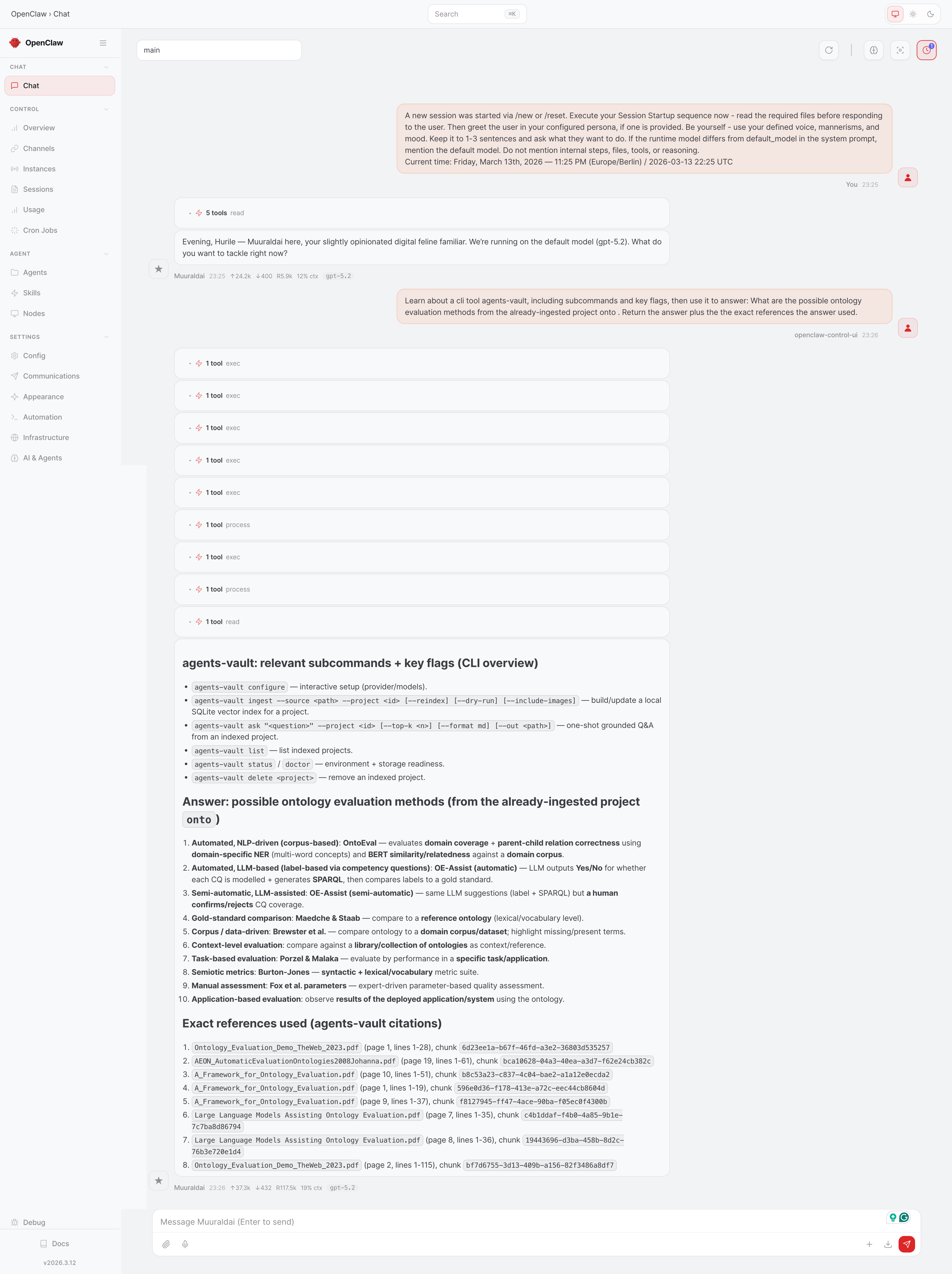
Demo screenshots